
Advanced Content Analysis: Can Artificial Intelligence Accelerate Theory-Driven Complex Program Evaluation?
2 | How Was Artificial Intelligence Used to Automate Content Analysis and Qualitative Synthesis?
Traditional Methods Used for Evaluation Synthesis
IEG thematic evaluations draw on project design and end-of-project evaluation documents. These are long narrative documents written by project teams and evaluation experts that draw on quantitative and qualitative data from multiple sources of experimental and nonexperimental methods. The reports are therefore qualitative and evaluative in nature and lack a standardized structure or labeling of specific results, except where logframes of key performance indicators are used.
Traditionally, systematic qualitative synthesis would be used to analyze this kind of evidence. This would normally involve reading all relevant documents and using thematic content analysis to code sections of the text against a conceptual framework. Coding may be done according to a predefined conceptual framework that seeks to confirm or reject hypotheses or evaluation questions (deductive). Alternatively, data may be coded from the ground up for exploration and understanding of what themes emerge from the content (inductive).
In practice, deductive and inductive coding can be used simultaneously or in sequence. However, inductive approaches tend to be less common because they require greater domain-specific expertise and deeper analysis, which is often only feasible on relatively few documents given the time required. Once all content is coded, the evidence within each code can be organized according to the conceptual framework. The framework is then reviewed to draw interpretations and conclusions.
This approach can be very time-consuming, even when using computer-assisted qualitative analysis software, and requires domain-specific expertise and methodological skills. It can therefore be costly and prohibitive for systematically analyzing large numbers of documents.
Artificial Intelligence Approaches to Automating Content Analysis and Qualitative Evaluation Synthesis
The pilot used natural language processing (NLP) methodologies to automate the process of thematic content analysis and explore the potential for NLP to complement traditional evaluation syntheses through greater speed, scope, and efficiency. NLP is a subset of AI technologies that enables computers to process and structure human language as natural language data, which can then be analyzed and interpreted in a meaningful way.
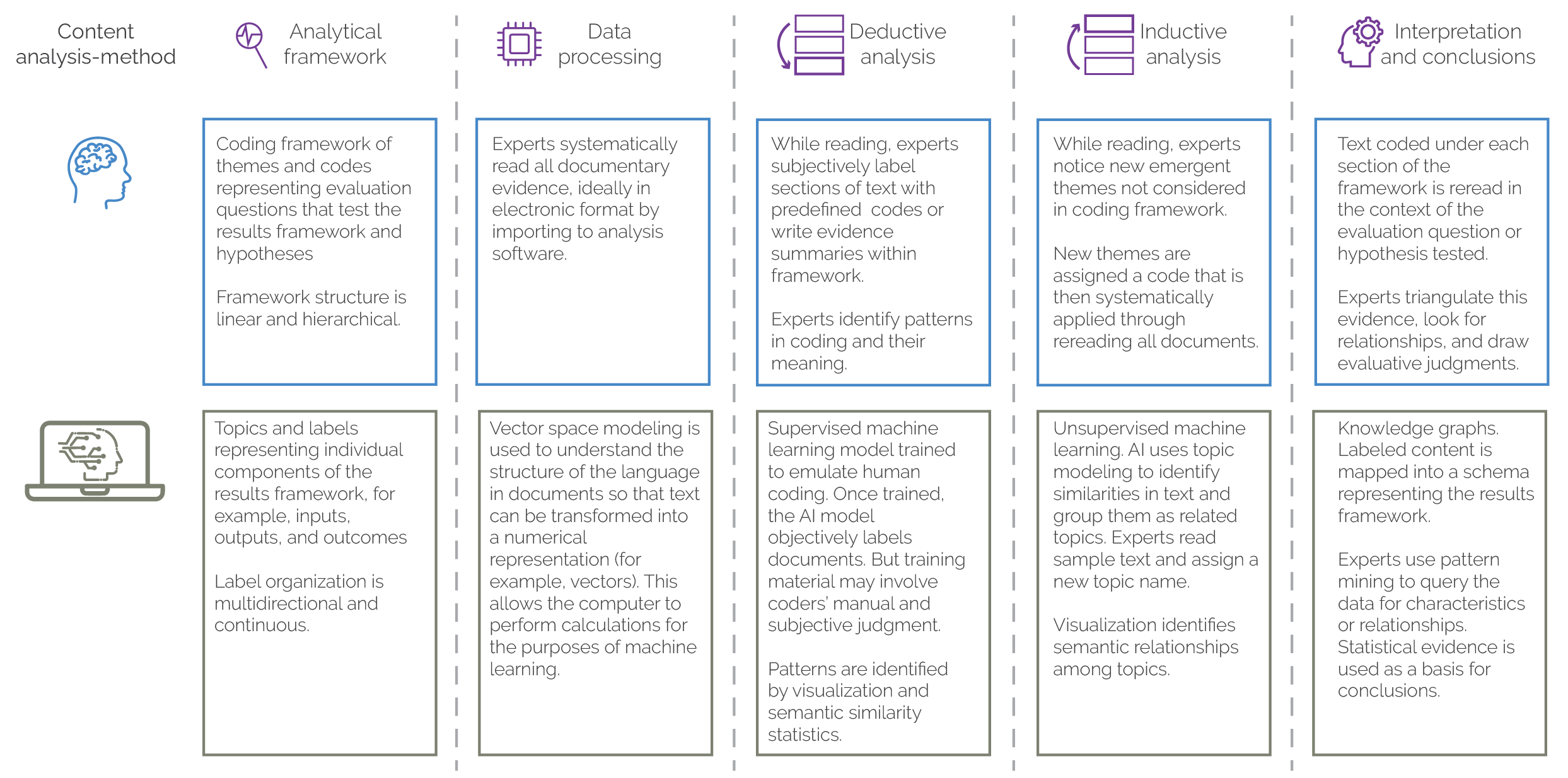
The AI methodologies used for NLP in the study included vector space modeling, supervised machine learning (SML), and unsupervised machine learning (UML), combined with knowledge graph approaches to perform an advanced theory-based content analysis of the project documents. A summary of how these methods compare with traditional evaluation synthesis methodologies is presented in figure 2.1.
Vector space modeling is a technique used in understanding the structure of language in documents so that text can be transformed into numerical representations (for example, vectors). Representing the text as a numerical vector allows the computer to perform calculations for machine learning.
SML is a deductive approach that uses training material to teach AI models to code content in a similar way. Once these patterns are learned from sufficient training samples for each code, the learned patterns are then applied to make coding predictions on new data outside of the training set. In the case of this study, subject matter experts prepared labeled examples of project documents and the SML made coding predictions on blocks of text from these documents. The performance of the AI model is then assessed by benchmarking the AI coding predictions against new material that is unseen during model training. When the AI performance reaches an acceptable threshold, the model can be deployed to undertake automated analysis on the full body of data.
UML contrasts with SML in that it is an inductive and data-driven approach. This study used topic modeling, a UML technique that allows related concepts to emerge from the data based on self-learning and semantic clustering. This approach makes few initial hypotheses about the concepts or meanings in the data and does not use training material to emulate the coding of human experts. Instead, topics are discovered based on statistical similarity measures in the word and sentence fragments. The usefulness of the UML approach is assessed through expert judgment on whether the emergent topics and codes are coherent and provide new insights that add to the interpretation of the evaluation evidence.
Knowledge graphs organize and integrate data on an entity of interest and structure it according to an ontological model known as a knowledge graph schema. Mapping data onto a model in this way allows connections and relationships among the data to be identified, analyzed, and better understood. Inferences can be drawn that rely on complex domain knowledge (represented by the knowledge graph schema), which is not possible when using machine learning classification methods alone. Knowledge graphs therefore work in complement with machine learning approaches to add context, depth, and reasoning ability that help explain the data-driven outputs of machine learning.
Figure 2.1. Comparison of Traditional and AI Approaches to Qualitative Evaluation Synthesis

Figure 2.1. Comparison of Traditional and AI Approaches to Qualitative Evaluation Synthesis
Source: Independent Evaluation Group.
Note: AI = artificial intelligence.