
Machine Learning in Evaluative Synthesis
Chapter 2 | Classification and Synthesis of Evaluative Evidence in the Independent Evaluation Group’s Finance and Private Sector Evaluation Unit
Objectives
IEG, an independent department within the World Bank Group, is charged with evaluating the activities of the World Bank (the International Bank for Reconstruction and Development and the International Development Association), the International Finance Corporation (IFC), and the Multilateral Investment Guarantee Agency. Specifically in regard to IFC’s work, IEG conducts desk-based exercises to validate IFC’s Investment Project Reports (Expanded Project Supervision Reports) and its Advisory Project Reports (Project Completion Reports). Three objectives drive the analysis outlined in this paper: (i) to support accountability by assessing the relevance, efficiency, and effectiveness of IFC’s projects; (ii) to support organizational learning by identifying lessons from experience to improve IFC’s operational performance; and (iii) to reinforce corporate objectives and values among IFC staff members.
Problem Statement
Automating the analysis of private sector project evaluations serves two major goals. First, we aim to build an automatic classifier so that the vast quantity of existing information in evaluation documents can be efficiently categorized according to distinct clusters of issues and challenges encountered in project implementation. Given the issues raised in chapter 1 related to the inefficiency of manual categorization, such an endeavor represents an intuitive next step in the parsing of evaluative evidence. Second, properly trained machine learning applications can help overcome issues related to intercoder reliability and evaluator subjectivity in classification. Based on the challenges of efficiency and accuracy discussed in the preceding chapter, automated classification and synthesis of project insights presents a viable solution for optimizing both the reliability and the objectivity of project analysis. The following sections summarize our methodological strategy, outline our implementation, and summarize our results.
Methodology
Using a combination of human expert knowledge and unsupervised- and supervised-learning algorithms (including naïve Bayes, random forest, support vector machine, and multilayer neural network methods), we generated a taxonomy of factors and issues that private sector projects typically encounter in regard to implementation. Approximately 1,600 documents evaluating private sector projects, produced between 2008 and 2022, provided our source input data for generating this taxonomy.
First, experts (IEG sector leaders with subject area expertise in the evaluation of projects in the financial, infrastructure, manufacturing agriculture and services, and funds sectors) discussed and shared the main factors and issues they faced in the development sectors in which they worked. We took the list of issues produced by the IEG sector leaders to conceptually account for the bulk of implementation issues private sector projects face throughout their life cycle. The sector leaders then manually classified these issues into five broad categories (country, market, sponsor, project specific, and other). Table 2.1 summarizes the taxonomy.
Table 2.1. Taxonomy of Project Insight (Categories)
|
Categories |
|
Country and macro factors |
|
Market, sector, and industry factors |
|
Sponsor or client (management, sponsorship, and leadership) |
|
Project-inherent challenges |
|
Other |
Source: Independent Evaluation Group.
Drawing on evaluation documents (specifically, IEG Evaluative Notes), we then extracted terms and concepts that were relevant to the issues identified, creating a matrix of keywords that was used to refine the experts’ draft taxonomy. In parallel, we applied automated text categorization to a list of more than 10,000 paragraphs to uncover potential subcategories from the corpus of supplied text. We used two unsupervised methods to complement the manual identification of conceptual categories. First, we used latent Dirichlet allocation (LDA) to find mixtures of terms for salient topics in the text. An evaluation officer compared the topics and key terms generated by LDA to the existing categories in our taxonomy, and it was found that four LDA-generated categories matched concepts identified by subject area experts. Keywords from those topics were added to the list of terms that would be used to identify those categories.1
Second, we used Google’s Word2vec model, which presents each term as a unique vector.2 The model can easily identify similar word combinations in common contexts by measuring their spatial proximity to generate clusters of concepts that are relevant to the analysis being undertaken. Figure 2.1 shows the Word2vec cluster for the concept of “expertise.” Using the interactive dashboard in the TensorBoard application, we then inputted keywords from our LDA and visualized the resulting word-proximity vectors in three-dimensional manifolds. Next, we compared the conceptual clusters generated by Word2vec with an existing keyword list created by an evaluation officer. Paired together, the resulting keyword matrix and modeled topics provided a preliminary assessment of the distribution of issues relating to private sector projects, how frequently they occurred in the documents, and how salient they were to the results the projects obtained.
Figure 2.1. Word2vec Word Cluster for “Expertise”
Figure 2.1. Word2vec Word Cluster for “Expertise”

Source: Independent Evaluation Group.
Figure 2.1. Word2vec Word Cluster for “Expertise”
Figure 2.1. Word2vec Word Cluster for “Expertise”
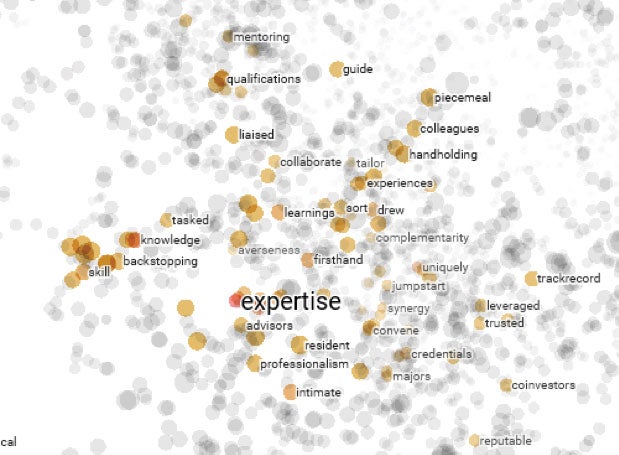
Source: Independent Evaluation Group.
This assessment fed back into the manual review of issue areas to help disaggregate the 5 categories into a set of 51 subcategories. The resulting taxonomy is shown in Table 2.2. Keywords associated with each of the subcategories were further refined by subject area experts to produce a training set for supervised machine learning classification. The classification procedure involved the following steps. First, we prepared the paragraphs for analysis by applying stemming, lemmatization, decapitalization, and stop-word removal. This eliminated small words such as “a,” “the,” and “and,” breaking down terms to their roots (for example, terms such as “history” and “historical” would be reduced to the common stem “histor-”). We also removed special characters and numbers to reduce the text to a set of cleaned “tokens” that could be used for classification according to the training set.
The training set was used for classification according to a set of different algorithms (naïve Bayes, random forest, support vector machine, and multilayer neural network), which were compared to assess their relative performance in classifying a new sample of paragraphs according to the subcategories generated. Given that the same sentence in an evaluation document could potentially be tagged with multiple relevant keywords, we used multilabel and multioutput text classification to cluster the keywords. Based on the results of this testing, we decided to use naïve Bayes for categorizing paragraphs, and specifically, for assigning a probability that a particular paragraph would be assigned to a particular category in the taxonomy.3
This approach was used to classify paragraphs in the corpus of 1,600+ documents, with the system generating some 85,000 classified paragraphs overall. To allow categorization of paragraphs to more than one theme, the classification assigned a primary, secondary, and tertiary subcategory alongside a probability of assignment to each.4 As an additional measure to aid categorization, we also used a sentiment analysis to assign a score to each paragraph, ranging between –1 (totally negative; paragraph includes information on a factor or issue that is a barrier or impediment to project implementation) and +1 (totally positive; paragraph includes information on a factor or issue that contributes to success in project implementation). This analysis was carried out using polarity scores from Python’s Natural Language Processing Package.
Table 2.2. Taxonomy of Project Insight (Categories and Subcategories)
|
Categories |
Subcategories |
Definition |
|
Country and macro factors |
Civil unrest and armed conflict |
Factors related to civil unrest, armed conflict, and war |
|
Economic factors |
Factors related to the macroeconomic environment, inflation, monetary policy, or austerity measures |
|
|
Epidemics and COVID-19 |
Factors related to epidemics (human, animal, and plant) and COVID-19 |
|
|
Expropriation, nationalization, and transferability |
Factors related to expropriation, nationalization, transfer, and convertibility |
|
|
Foreign exchange and local currency factors |
Factors related to currency fluctuation, exchange rate and local currency issuance instruments |
|
|
Legal or regulatory factors |
Factors related to regulatory policies, government, legislation, and bureaucratic mechanisms |
|
|
Natural disasters |
Factors related to natural disasters such as hurricanes and earthquakes |
|
|
Political factors |
Factors related to the political environment, including legislative and electoral dynamics |
|
|
Market, sector, and industry factors |
Business factors |
Factors related to business model, cyclical business, or the operating environment |
|
Competition |
Factors related to market competition: barriers to entry, monopolies, market dominance, and penetration |
|
|
Customers |
Factors related to identifying correct target markets and clientele |
|
|
Market share |
Factors related to market share |
|
|
Pricing |
Factors related to price elasticity, supply, and marginal gains |
|
|
Sponsor or client (management, sponsorship, and leadership) |
Capacity, capitalization, leverage |
Factors related to sponsor capacity, capitalization, and leverage |
|
Commitment and motivation |
Factors related to the strength and valence of strategic alignment, including compatibility, motivation, and ownership |
|
|
Conflicts of interest, corporate governance |
Factors related to minority interest, conflicts of interest, and corporate governance |
|
|
Integrity, transparency, fairness, reputation |
Factors related to integrity and transparency, such as disclosures of sensitive ethical issues, irregularities, and negative public perceptions |
|
|
Organizational structure |
Factors related to organizational culture, institutional procedures, policies, and accountability |
|
|
Technical expertise, track record, and capacity |
Factors related to the quality and expertise of the management team, their technical skills and track record, and contractor competency, familiarity, and acumen |
|
|
Succession |
Factors related to succession, especially in family-owned businesses |
|
|
Project-inherent challenges |
Asset quality |
Factors related to asset quality |
|
Cost overruns and delays |
Factors related to overruns or delays |
|
|
Earnings and profitability |
Factors related to earnings and profitability |
|
|
Environment and sustainability |
Factors related to environmental standards, social health and safety parameters, or other safety standards |
|
|
Expansion |
Factors related to acquisition, modernization, and expansion |
|
|
Funding |
Factors related to funding |
|
|
Greenfield |
Factors related to greenfield projects |
|
|
Gender |
Factors related to gender |
|
|
Liquidity |
Factors related to liquidity |
|
|
Technology |
Factors related to changes in technology that affected project performance |
|
|
Training, know-how, and implementation |
Factors related to training and know-how |
|
|
Other |
Additionality principle and catalytic rolea |
Factors related to additionality and added value |
|
Coordination and collaboration with World Bank Group, other DFIs, donors, and other external stakeholders |
Factors related to combined partnership and collaboration among the various stakeholders: the World Bank Group, donors, DFIs, and other external stakeholders |
|
|
Coordination and collaboration within IFC: AS-IS |
Factors related to use of investment and advisory services to enhance IFC roles and contributions |
|
|
Project scoping and screening; country and stakeholder assessment; client needs assessment |
Factors related to ex ante market analysis, due diligence, and consumer preferences |
|
|
Client selection, commitment, and capacity |
Factors related to client or implementing-partner selection (appropriateness) and client commitment and involvement |
|
|
Project design |
Factors related to project design |
|
|
Financial model, project cost, and sensitivity assumptions |
Factors related to financial modeling assumptions, including issues regarding overambitious objectives, deviations from forecasting estimates, and scaling |
|
|
Market assessment |
Factors related to market assessment, market analysis, and consumer preferences |
|
|
Resources and timeline |
Factors related to staffing, budget, and timeline |
|
|
Supervision and reporting |
Factors related to (i) supervision and reporting; and (ii) taking measures to enhance these, as well as proactive client and stakeholder follow-up |
|
|
Sensitivity analysis |
Factors related to sensitivity analysis, worst-case scenarios, stress tests, and risks to achieving development outcomes |
|
|
Documentation |
Factors related to the quality of monitoring, documentation, and reporting |
|
|
Loan issues |
Factors related to loan agreements, operating policies, breaches, and technical defaults |
|
|
Relationship management |
Factors related to the quality and scope of relationship management, including fruitful and proactive engagements with on-site staff |
|
|
Debt issues |
Factors related to debt issues, such as syndication, repayment, security, and refinancing |
|
|
Equity issues |
Factors related to equity, valuation, and shareholder rights |
|
|
Financial risk mitigation |
Factors related to risk-mitigation mechanisms such as guarantees, securities, prepayment penalties, and restructuring mechanisms |
|
|
Prepayments |
Factors related to prepayments |
|
|
Monitoring and evaluation |
Factors related to compliance, monitoring including measurement, reporting, auditing, monitoring and evaluation plan and framework, appropriate indicators and targets, and clarity of data collection and evaluation approach |
|
|
Other issues |
Factors related to other issues |
Source: Independent Evaluation Group.
Note: a. The latest guidance on additionality can be found at https://km.ifc.org/sites/pnp/MainDocumentMigration/DI716AdditionalityFramework.pdf.AS = advisory services; DFI = development finance institution; IFC = International Finance Corporation; IS = investment services.
Model Refinement
It should be noted that the initial classification exercise yielded low-accuracy results. This may be related to two possible causes. First, the unrefined taxonomy originally included 81 subcategories, before the manual validation described earlier. This meant that many subcategories were too sparsely populated to enable accurate identification of themes. Second, some of the keywords selected for use in classification occurred too commonly in evaluation documents to provide meaningful information for the models. By their nature, some of the themes included in the taxonomy overlapped conceptually. For example, the subcategories “client selection, commitment, and capacity” and “monitoring and evaluation” could be considered integral parts of the category “project-inherent challenges” as well as of the category “other,” where they appear in our taxonomy. This required manual review to separate the themes (where possible) and refine the keywords.
Given the large number of subcategories generated in the taxonomy, several steps were taken to iteratively refine it to improve classification precision and relevance. This yielded the smaller taxonomy of 51 categories shown in table 2.2. First, the subject area experts addressed deficiencies by either formulating new subcategories or deleting irrelevant or less-frequently occurring ones, expanding or consolidating categories when needed, and updating definitions. This helped us to avoid including catchall categories that would make the resulting classifications of issues discussed in project documents less meaningful.5 Likewise, the removal of subcategories with very few observations helped make the taxonomy more manageable.6 At the same time, the training set was refined to eliminate catchall words and phrases to improve classification precision. For example, manual classification led to more than 15 percent of the initial paragraphs being assigned to the subcategory “IFC work quality.” We therefore assessed this subcategory as a catchall and divided it into several different subcategories, such as “market assessment,” “sensitivity analysis,” and “financial model, project cost, and sensitivity assumptions.”
Streamlining and refinement of model subcategories also involved additional diagnostics like cosine similarity. Cosine similarity analysis is a heuristic method of the distinctiveness of the vocabulary associated with a particular concept and can be used to identify categories that are problematically correlated with each other. Cosine similarity was used to find areas where underlying keywords or phrases used in conceptually distinct topics created issues in regard to classification accuracy: although the topics themselves might be conceptually distinct, the use of similar terms to identify relevant passages would result in overlaps among groups that reduce classification accuracy. In the case of high similarity scores, we checked keywords and categories to ensure that the groups identified in the taxonomy were (to the extent possible) mutually exclusively defined. After a few iterations, we were able to eliminate several categories with problematic overlaps, further improving the subcategories in the taxonomy.
The model refinement process offered three main benefits. First, it ensured that most categories were reasonably well balanced with respect to the number of paragraphs classified into them. Second, it improved the quality and informativeness of text tags and examples used in classification. Third, it generated sufficient observations per subcategory to allow for the exploratory and descriptive statistical analysis of lesson categories. After this recalibration, the subcategory with the maximum number of paragraphs represented about 6 percent of the total population of paragraphs, and the average subcategory included about 2 percent. Classification accuracy improved to an average of about 70 percent across the refined subcategories.
Summary of Results
The results of the automated classification and synthesis procedure were compared against hand-coded samples generated by subject experts. Table 2.3 provides an illustration of the results of this analysis.
Table 2.3. Comparison of Hand-Coded (Human) and Machine-Coded Classification
|
Factor |
Subcategory |
Text |
|
Human Coding |
||
|
Factor 1 |
Legal or regulatory factors |
Lack of a properly regulated public transportation system led to uncertainty and high risk regarding the setting of fares and payment of subsidies. |
|
Factor 2 |
Political factors |
Effective nationalization of [Company X] within the country operation. Cancellation of license (Country CDE Operation). |
|
Machine Coding |
||
|
Factor 1 |
Legal or regulatory factors |
Lack of a properly regulated public transport system (at the national or municipal level) leads to uncertainty and therefore high risk regarding the setting of fares and payment of subsidies. The project was expected to have a demonstration effect for other governments and municipalities and encourage similar public private partnerships. |
|
Factor 2 |
Legal or regulatory factors |
An attempt could be to have the legal agreement (between the government agency and the company) subject to an outside jurisdiction. It needs to ensure that there is a functioning regulatory authority that determines the amount and timing of fare increases and subsidy payments. This should be (and act) as legally independent of local and/or national governments. |
|
Factor 3 |
Legal or regulatory factors |
Subsidy turned out to be critical for the project. Take the form of international law governing the documents, or the presence of a strong independent regulatory authority in an environment where the judiciary is also strong and independent. If no effort to protect the project is undertaken, then it is subject to the changing whims of local regulators. |
|
Factor 4 |
Legal or regulatory factors |
[Company X] could not meet its performance targets owing to "operational and regulatory difficulties with the regulator" as the government refused to pay the subsidies agreed upon or increase the agreed-upon tariffs. |
|
Factor 5 |
Political factors |
Nationalization of [Company X] and cancellation of the license smacks of political interference and sets a lasting, negative effect which would deter future private investment in the public transport sector in both countries. |
|
Factor 6 |
Political factors |
The project was structured through the parent operation and provided some insulation against project-level risks. Nevertheless, from a development perspective this oversight exposed the project to high and unmitigated political risk. |
|
Factor 7 |
Political factors |
The political movement had a significant political and financial impact on the country, with (among other things) several national government changes. It is very difficult to structure a project so that it achieves its development objectives while going through a once-in-a-generation political and social revolution. |
|
Factor 8 |
Political factors |
The project relied on two important factors: (i) subsidies from FGH and (ii) implementation of agreed tariff increases. The subsidy only amounted to a small portion of receipts from traffic violations and thus this was not seen as an issue. Without control mechanisms, the project was entirely reliant on political will which is uncertain at best and was completely lacking after the political movement. |
|
Factor 9 |
Expansion |
[Company X] was to invest approximately US$[X] million to modernize their facilities and expand their fleet. The loan was disbursed in two tranches. |
|
Factor 10 |
Expansion |
[Company X] planned to invest US$[X] million, most of it in the form of a capital increase. Additional investment as well as capital provided by the existing shareholders to modernize its facilities and expand its fleet. |
|
Factor 11 |
Expansion |
[Company X], as the part of an expansion plan, signed an agreement to invest US$[X] million through a capital increase. The capital increase would be used toward financing a capital expenditure program over the coming years with modern maintenance facilities, as well as a major fleet renewal and expansion. |
|
Factor 12 |
Additionality principle and catalytic role |
The project went ahead without adequately mitigating development risks (as distinct from the credit risks) as both deserve equal attention given the corporate mandate and purpose. |
|
Factor 13 |
Additionality principle and catalytic role |
It was expected that the project would have a strong developmental impact with increased transport access to the urban poor and the disabled, leading to improvements in service levels overall. In addition, the project was expected to encourage other governments and municipalities to create public-private frameworks. |
Source: Independent Evaluation Group.
Note: Firm names and specific dollar amounts are withheld for reasons of confidentiality.
As expected, the model showed a high degree of accuracy in classifying content into well-defined subcategories such as “legal or regulatory factors,” “political risk,” and “market share,” whereas classifications into less well-defined categories such as “commitment and motivation” yielded a higher number of false positives. Overall, classification according to supervised machine learning techniques offered clear advantages over manual classification of factors and issues in project implementation. Manual classification relies on individual practitioners, each drawing on a set of unique theoretical priors, influenced by knowledge and experience that could potentially affect the way they search evaluation documents for factors and issues in implementation.
Furthermore, human coders focus on high-level or highly salient issues with greater frequency, potentially ignoring substantively meaningful but more subtle features that evaluation documents may also discuss. Drawing on a vetted training subset, supervised learning generated considerably higher classification efficiency than human coding with a comparable degree of accuracy. Properly calibrated machine analysis produced faster and more efficient synthesis of evaluative evidence.
After this initial test was undertaken, IEG undertook a wider analysis, with both human coders and algorithms classifying content in more than 170 Evaluative Notes published between 2020 and 2022 across four industries in which IFC funds projects (Financial Institutions Group; Manufacturing, Agribusiness, and Services; Infrastructure and Natural Resources; and Disruptive Technologies and Funds). Human coders were asked to include (i) the top three factors (taxonomy subcategories) that explained the success or failure of a project in terms of achieving its desired development outcome, organized from most important to least important; (ii) the direction in which each factor (subcategory) affected project success (+1 if the factor supported project success, –1 if the factor presented a risk affecting a project); and (iii) a copy of the paragraph from the Evaluative Note that supported why a factor (subcategory) was chosen.
Once the initial coders had classified the content in their project documents, a specialist or sector leader validated the classifications, as a form of peer review intended to make classification consistent across the four IFC industry groups. There was also an additional review across industries to make sure that classifications were consistent over the total portfolio of Evaluative Notes analyzed.
After human coders had classified the content in the Evaluative Notes and their classifications had been reviewed as discussed in the preceding paragraph, the same machine learning protocol was applied to the content. The average accuracy of machine-generated classification was about 70 percent across the subcategories evaluated, with classification in some subcategories such as “economic factors,” achieving greater than 90 percent accuracy.7
To ensure the relevancy and adaptability of our machine learning model against the evolving risk landscape, model performance is assessed periodically to reflect new evidence and adapt the subcategories in our taxonomy. Rigorous quality and change control procedures are in place to ensure the robustness, stability, and reliability of the model output.
Limitations
No methodology is without flaws, and machine learning is no exception to that rule. This section outlines some of the limitations to the approach explored in this paper. As discussed earlier, the inclusion of many overly granular subcategories resulted in low accuracy rates, especially in areas where there were very few observations to help classify a particular concept. We addressed issues of excessive granularity through a refinement of problematic subcategories. In addition, the use of diagnostics like cosine similarity ensured that the remaining categories were conceptually exclusive. However, this also implied that some of the nuances requested by subject experts and practitioners had to be omitted from the taxonomy. In those cases, the subcategories were often too subtle or complex to allow for accurate classification.
The output of a supervised model is only as good as the reliability of training data inputted. There are numerous pathways to suboptimal machine classification, but sufficient diligence and meticulous calibration of input parameters can guard against more pernicious errors and biases. If overarching categories in the taxonomy were not well defined or not mutually exclusive, the machine learning algorithm had difficulty in categorizing content into them accurately. Two examples illustrate this point. First, the model initially omitted the classification of factors and issues related to advisory services projects. When it became clear that the initial taxonomy was insufficiently equipped to classify such factors and issues, we modified the subcategories to address the omission. Once pertinent examples of such factors and issues had been provided to train the model, machine learning was then successfully used to identify other instances of similar issues. Second, the model initially used overly broad keywords, such as, “commitment” as a keyword in the subcategory “commitment and motivation.” This resulted in an overestimation of challenges related to that subcategory, as commitment can mean “the state or quality of being dedicated to a cause, activity, and so on,” but can also mean “obligation to provide a pledged amount of capital.” Its prevalence in evaluation reports therefore made it an inefficient classifier for machine learning applications. In both cases, we identified and corrected for this type of error through cross-validation of the output data and providing the machine learning algorithm with examples instead of keywords.
- Though relatively efficient, the latent Dirichlet allocation approach often generated groupings without a clearly interpretable significance. While these clusters could have represented potential categories, they were more likely a by-product of random associations without significant substantive meaning. We therefore omitted them from the analysis.
- Google developed Word2vec to reconstruct the linguistic context of sentence fragments. It maps inputted text data into a vector space.
- We used the four algorithms to classify paragraphs that human experts had previously classified, and the algorithm with results closest to those of the manual classification was naïve Bayes.
- For example, in cases in which a paragraph spoke exclusively about “economic factors,” then the probability for that subcategory would be 100 percent, and the probability for the next two categories would be 0 percent. In one example in which the majority of the paragraph was about economic factors, the probabilities assigned were 70 percent for “economic factors,” 20 percent “foreign exchange and local currency factors” and 10 percent “legal or regulatory factors.”
- After refinement, average per-subcategory inclusion rates approached 2.0 percent, and the most broadly defined subcategory had an inclusion rate of 6.0 percent. To correct for the inclusion of frequent but substantively uninformative categories, we normalized the frequency with which categories were predicted by dividing the number of predictions for a particular category by the overall distribution of the predicted categories in the universe of coded keyword tags. We then chose the categories that had greater than 1.2 times the average along the distribution. This yielded a workable hierarchy of the most salient factors included in each document.
- We eliminated any subcategories that included fewer than 50 paragraphs or merged them with conceptually proximate categories to increase identification accuracy. For example, we merged the subcategories “conflicts of interest” and “corporate governance,” as we found that they were both capturing similar concepts and each accounted for less than 1 percent of total paragraphs classified.
- It should be noted that certain subcategories continued to perform suboptimally, even after modeling refinements were applied. In several cases, machine learning generated a substantial volume of false positives that required additional manual validation. Part of this relates to the trade-off between completeness and classification accuracy: although the lower performing subcategories may be of conceptual interest, there are certain limits to the quality of categorization output that are highly dependent on the keywords and phrases that can be used to correctly identify a concept. In some cases, these nuances are too subtle to be picked up by machine coding.